Telecommunications networks and services become more and more complex
and heterogeneous. Mobility and ubiquity require the transparent integration
of diverse technologies and architectures. Management is therefore
evolving from a heavily manual and centralized activity to an automatic
one, with highest added value for operators and equipment suppliers. Cross-domain,
and even cross-operator, management with end-to-end guarantees requires
a distributed and adaptive approach. It is envisioned that distributed
management will play a strong role in managing complex networks where the
distribution of the various aspects of management such as monitoring, configuration,
provisioning, billing, fault, and performance becomes imperative for greater
reliability, scalability and efficiency. The emergence of Web services
extends the traditional scope of network and service management. The generic
term of
self-management encompasses all
aspects of flexible distributed management.
The following four aspects of self-management have been identified,
in which the need for and the purpose of
autonomic computing become apparent:
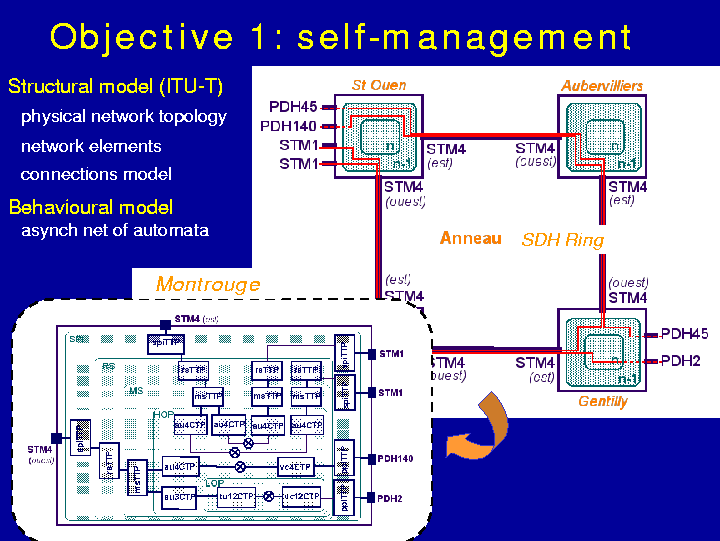
This figure shows the SDH/SONET optical ring in operation in the Paris area (the locations indicated are suburbs of Paris). A few ports and links are shown. The bottom-left diagram is a detailed view of the Montrouge node. The nested light to mid gray rectangles represent the different layers in the SDH hierarchy, with the largest one being the physical layer. The different boxes are the managed objects (MO), and the links across the different layers are the paths for upward/downward fault propagation. Each MO can be seen as an automaton reacting to input events/messages, changing its state, and emitting events and alarms to its neighbors, both co-located and distant.
To give some figures related to system complexity, each network node
is an asynchronous network of automata; each automaton has a handful of
states; and there are from hundreds to thousands of such automata in the
network. Each root fault can cause hundreds of correlated alarms that travel
throughout each subsystem and are collected by the corresponding local
supervisor. Supervised domains may very well be orders of magnitude larger
in the future. Thus,
scalability is a major concern. It is important that the type of algorithm
we develop takes this context into account.
To correlate faults and alarms that are causally related, our distributed algorithms use behavioral models of the system - this feature holds for fault management, but is also valid for other functions requiring non trivial algorithms. Therefore, the first issue is that of how to construct such models, since this cannot be performed manually. This is the subject of what we call self-modeling.
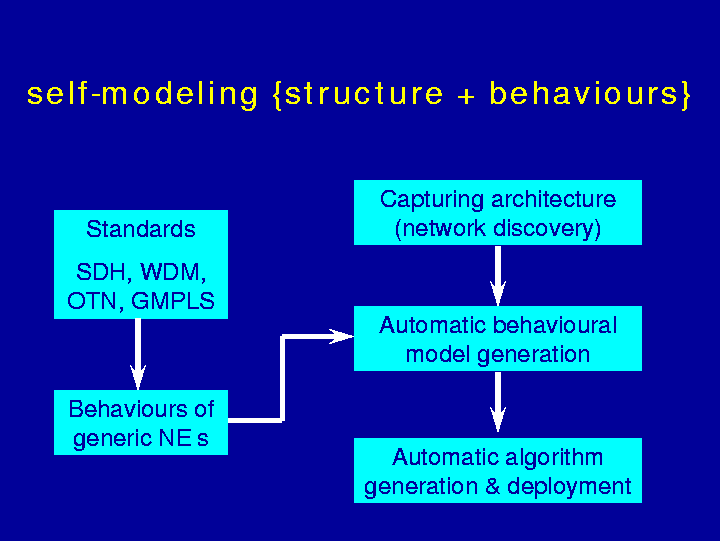
The existence of standards allows us to build (a dozen of) classes of generic managed objects, with their associated behaviors. From performing network discovery, the structure of the management system can be found. From these two inputs, a behavioral model for the entire system can be automatically generated, as well as the distributed algorithm for fault diagnosis.