Image compression with Stochastic Winner-Take-All Auto-Encoder
"Image compression with Stochastic Winner-Take-All Auto-Encoder", ICASSP 2017, submitted.
contact:
T. Dumas, A. Roumy, C. Guillemot
Abstract
This paper addresses the problem
of image compression using sparse representations. We propose a
variant of auto-encoder called Stochastic Winner-Take-All Auto-Encoder
(SWTA AE). "Winner-Take-All" means that image patches compete
with one another when computing their sparse representation and "Stochastic"
indicates that a stochastic hyperparameter rules this competition during training.
Unlike auto-encoders, SWTA AE performs variable rate image compression for images
of any size after a single training, which is fundamental for compression.
For comparison, we also propose a variant of Orthogonal Matching Pursuit
(OMP) called Winner-Take-All Orthogonal Matching Pursuit (WTA OMP).
In terms of rate-distortion trade-off, SWTA AE outperforms
auto-encoders but it is worse than WTA OMP. Besides,
SWTA AE can compete with JPEG in terms of rate-distortion.
Stochastic Winner-Take-All Auto-Encoder (SWTA AE)
Stochastic Winner-Take-All Auto-Encoder (SWTA AE) is a type of auto-encoder. An auto-encoder is a neural network that takes an input and provides
a reconstruction of this input. SWTA AE is a fully-convolutional auto-encoder so that it can compress images of various sizes. The
central bottleneck of SWTA AE, denoted Z in the figure below, will be further processed to deliver the bitstream. Z contains 64 sparse
feature maps, displayed in orange in the figure below, and one non-sparse feature map, displayed in red. The 64 sparse feature maps are computed via a Winner-Take-All (WTA) competition and a WTA parameter
gives control over the coding cost of Z. During training, the WTA parameter is stochastically driven so that, after training, SWTA AE is able to compress at any rate.
SWTA AE architecture 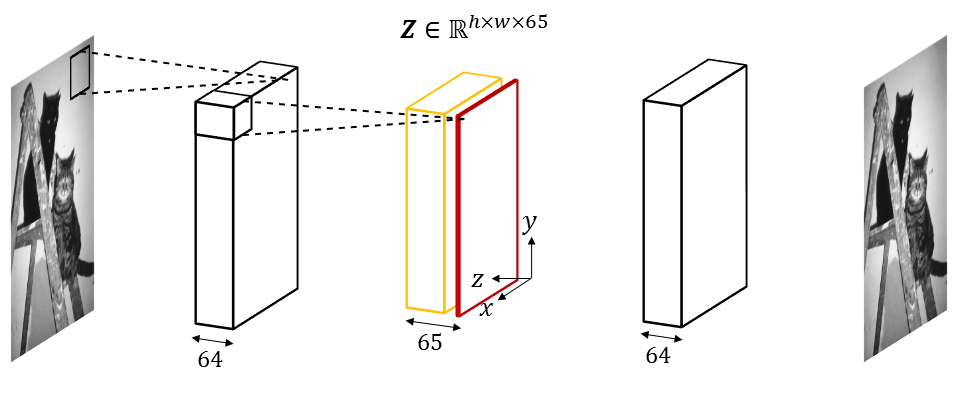 |
Winner-Take-All Orthogonal Matching Pursuit (WTA OMP)
The WTA competition is adapted to Orthogonal Matching Pursuit (OMP), giving rise to
Winner-Take-All Orthogonal Matching Pursuit (WTA OMP).
Training
The training set of luminance images is built from
the ILSVRC2012 ImageNet dataset. SWTA AE learns its parameters. A dictionary for OMP and a dictionary for WTA OMP are
learned using respectively K-SVD and our proposed dictionary learning algorithm for WTA OMP.
Visualization of the bottleneck feature maps of SWTA AE after training
Non-sparse feature map in the bottleneck
of SWTA AE when SWTA AE is fed with LENA luminance 320x320  |
First four sparse feature maps in the bottleneck
of SWTA AE when SWTA AE is fed with LENA luminance 320x320 
 
 |
SWTA AE learns to store in the non-sparse feature map of Z
a subsampled version of its input image. Apparently, the non-zero coefficients in the sparse feature maps of Z are
agglomerated around the spatial locations where the most complex textures are found in the input image.
Visualization of the learned dictionaries
Dictionary of 1024 atoms learned using K-SVD  |
Dictionary of 1024 atoms learned using the dictionary learning algorithm for WTA OMP  |
The two dictionaries look different. The dictionary learned using the dictionary learning
algorithm for WTA OMP contains more diverse atoms around high frequencies. This justifies the utility of this dictionary algorithm.
Image compression experiment
Comparison of rate-distortion curves
We compare the rate-distortion curves of OMP,
WTA OMP, SWTA AE, the non-sparse Auto-Encoder (AE), JPEG and JPEG-2000 on four standard
luminance images. These luminance images have different sizes to see whether SWTA AE can
handle the change of input size. Note that, before drawing a new point at a different rate in
the rate-distortion curve of AE, AE must be re-trained with a different number of feature maps
in its bottleneck.
LENA luminance 320x320 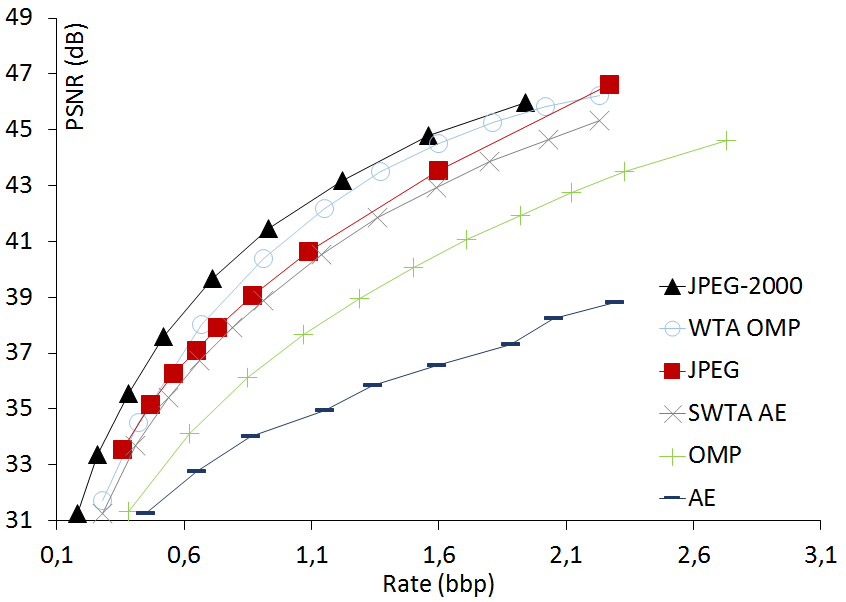 |
BARBARA luminance 480x384 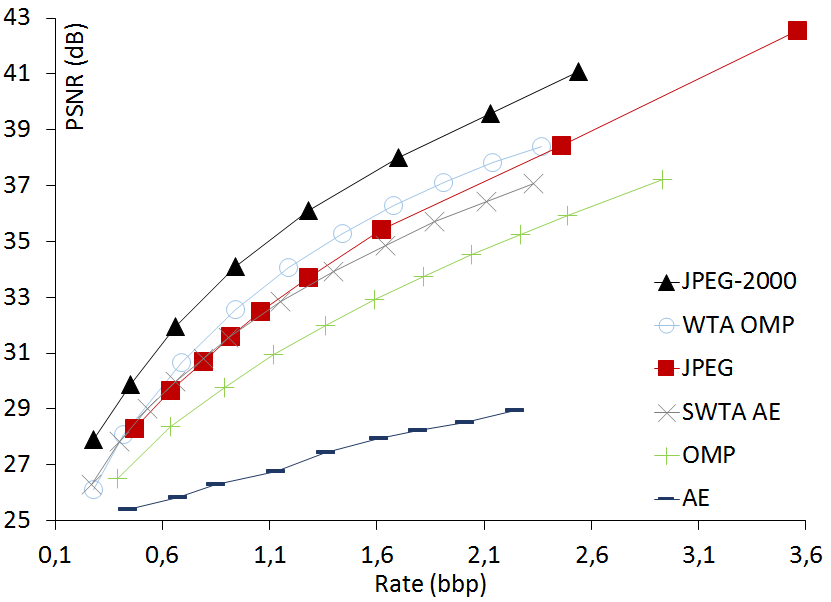 |
MANDRILL luminance 400x400 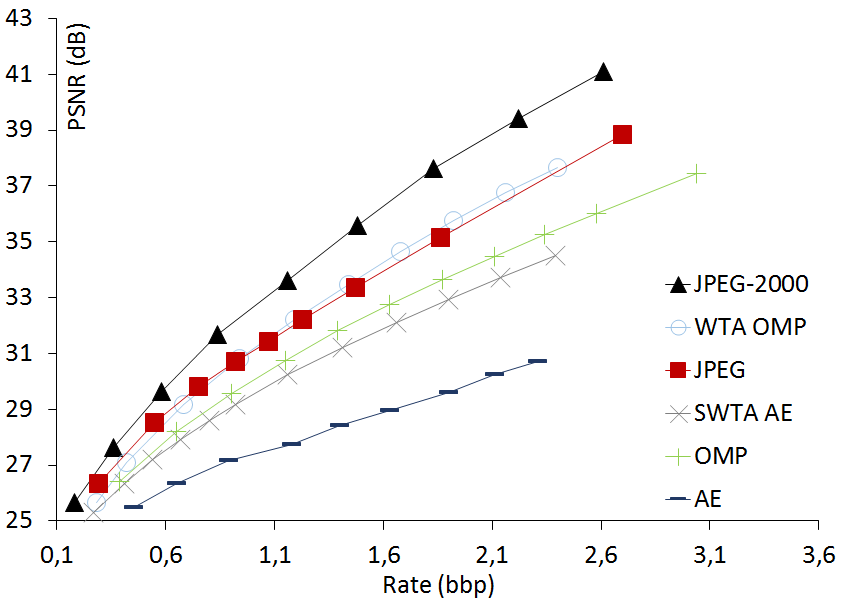 |
PEPPERS luminance 512x512 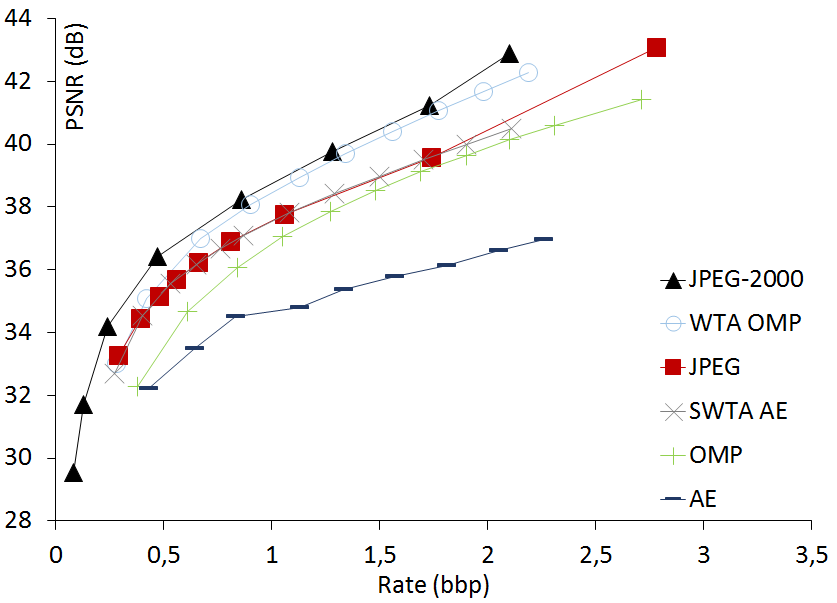 |
Visualization of image reconstruction
LENA luminance 320x320 (original)  |
JPEG-2000 (PNSR = 41.46 dB, rate = 0.93 bbp)  |
SWTA AE (PNSR = 38.90 dB, rate = 0.91 bbp)  |
JPEG (PNSR = 39.06 dB, rate = 0.87 bbp)  |
BARBARA luminance 384x480 (original)  |
JPEG-2000 (PSNR = 34.09 dB, rate = 0.94 bbp)  |
SWTA AE (PSNR = 31.57 dB, rate = 0.91 bbp)  |
JPEG (PSNR = 31.60 dB, rate = 0.92 bbp)  |
For BARBARA, SWTA AE reconstructs well the scarf, the wicker chair and the tablecloth but
struggles to reconstruct BARBARA's left harm and the shadow of the table.