


Goals, Results, and Deliverables
Big Data evolution, the introduction of cloud computing and the success of the MapReduce model have fostered new types of data-intensive applications where obtaining fast and timely results is a must (i.e., stream data applications). Stream data applications are emerging as first-class citizens in large scale production data centers (e.g., click-stream analysis, network-monitoring log analysis, abuse prevention, etc).
Hadoop has recently emerged as by far the most popular middleware for Big Data processing on clouds. But Hadoop can not deal with low-latency stream processing because data needs to be stored in the distributed file systems. While several systems has been introduced to process stream data applications, they are still providing best efforts when failures occur (failure is a natural reflection of the explosion of scale) . Moreover, they are designed to run on dedicated "controlled" environments and therefore suffer of unpredictable performance when running on large-scale clouds due to the resource contention, performance variation and high rate of failures.
The KerStream project aims to address the limitations of Hadoop, and to go a step beyond Hadoop through the development of a new approach, called KerStream, for reliable, stream Big Data processing on clouds. KerStream keeps computation in-memory to ensure the low-latency requirements of stream data computations. Furthermore, KerStream will embrace a set of techniques that allow the running applications to automatically adapt to the performance variation and node failures/subfailures, and enable a smart choice of failure handling techniques. Moreover, KerStream will have a set of scheduling policies to allow multiple running applications to meet their QoS (low-latency for stream data processing) while achieving high resource utilization.
Current results and Deliverables
This project aims to address the limitations of Hadoop when running stream data applications on clouds and to go a step beyond Hadoop by proposing a new approach, called KERSTREAM, for fast, resilient, and scalable stream data processing on clouds. We expect this project to bring substantial innovative contributions with respect to the following aspects:
[Objective 1] An approach for fast and scalable stream data processing on clouds.
ANR Funded Participantes: Thomas Lambert, David Guyon, Jad Darrous
We plan to design a new approach for in-memory stream data processing, named KerStream. Different from other stream data processing frameworks (e.g., Spark and Flink) which are designed for a controlled environment (assume homogeneous resources), KerStream will be equipped with a performance-aware task scheduling framework to cope with the unpredictable performance variably in clouds (network, I/O, etc).
[D1.1] Towards the design of an architecture for scalable in-memory stream data processing, we have performed the below studies:
First, we evaluated the performance of Spark (widely used Big Data analysis engine) in different environments (i.e., cloud where the storage is attached to the compute nodes and HPC where the storage is separated from the compute node) and we have explored how to use in-memory buffer systems to improve the performance in the later scenario. This work was realized in collaboration with Orcun Yildiz and Amelie Chi Zhou and resulted in three publications in Cluster 2017, FGCS 2018 and SCA 2018.
Second, we performed a performance characterization study of RamCloud which is a representative in-memory storage system featured with low latency and is actually a potential candidate to store data when processing stream data applications. This study will help in completing the picture and identify the most appropriate in-memory storage system for in-memory stream data processing engines.This work was realized in collaboration with Yacine Taleb and resulted in one publication in ICDCS 2017.
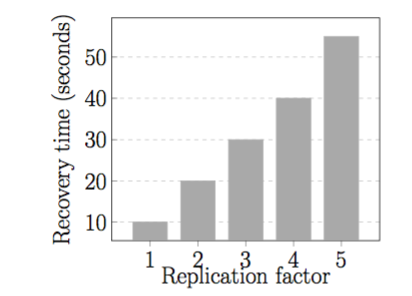
Third, we have investigated erasure coding as a scalable yet cost-efficient alternative for replication in data-intensive clusters. This work was realized in collaboration with Jad Darrous and resulted in one publication in MASCOTS19.
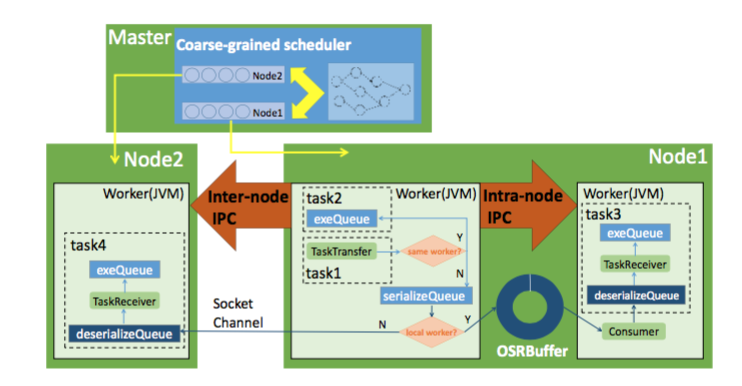
Fourth, we investigate the performance benefits of FPGA for distributed stream processing system. This work was realized in collaboration with Hai Jin and Wu Song and resulted in one publication in ICDCS 2019 (Vision paper).Given the insights of the above-mentioned work, we decided to rely on simulation and also mature open source stream data engine in our project. In addition, we identified several factors which severely impact the performance of stream data applications including data bursts, inter-node communications and network heterogeneity. Accordingly, we have introduced two approaches to reduce the latency of Stream data processing though reduce memory-copy operations and efficiently handling data bursts.
This work was realized in collaboration with Hai Jin and Wu Song and resulted in two publications in ICDCS 2018 and ICPP 2018.[D1.2] We made the data sets of the large scale experiments which we have conducted to understand the performance issues of scalable in-memory stream data processing publicly available online. In addition, we are going to release the source code of the simulation for stream data application.
[D1.3] First, we introduce a new method for graph partitioning that addresses the high latency and heterogeneity and thus improves the response time of graph processing applications. We plan to port the results to stream processing application, especially as data stream processing applications are often modelled as a directed acyclic graph: operators with data streams among them. This work was realized in collaboration with Amelie Chi Zhou and Bingsheng He and resulted in two publications in ICDCS 2017 and TPDS 2019.
With Thomas Lambert and David Guyon, we developed a performance-aware task scheduling which place operators considering the network heterogeneity and node capacities (paper in CIKM 2020). We are now finalizing the implementation of our solutions on the top of Storm (mature and widely used stream data engine ) [D 1.2] [D 4.1] and going to perform large scale validation [D 4.2].
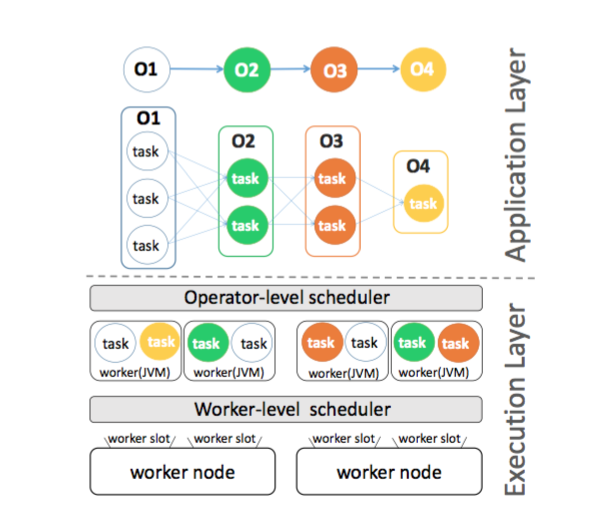
[Objective 2 ] A smart configurable failure/subfailure recovery.
ANR Funded Participantes: Thomas Lambert, David Guyon, Twinkle Jain
We will propose a set of techniques (e.g., machine learning techniques) and algorithms that allow stream data processing to automatically adapt to node failures and subfailures (i.e., Stragglers) and to enable the “smart” choice of failure/subfailure handling techniques.
[D 2.1] We introduce a set of metrics dedicated for characterizing the straggler detection and understanding its inherent attributes. Besides, we present a mathematical intuition for connecting the proposed metrics to their execution characteristics (i.e., performance). This work was realized in collaboration with Tien-data Phan and Guillaume Pallez and resulted in one publication in ACM TOMPECS 2019. We also made the traces publicly available.
[D 2.2] We have investigated a new technique to handle stragglers and also introduced a new scheduling framework to handle stragglers in heterogeneous environments.
This work was realized in collaboration with Tien-Dat Phan, Amelie Chi Zhou and Bingsheng He and resulted in two publications in Euro-Par 2017 and ICPP 2018. With Twinkle Jian, Thomas Lambert and David Guyon, we have extended our work to Spark and we are currently investigating new optimisations based on heartbeats arrival and using DMTCP, in collaboration with one of our supporter Gene Cooperman.
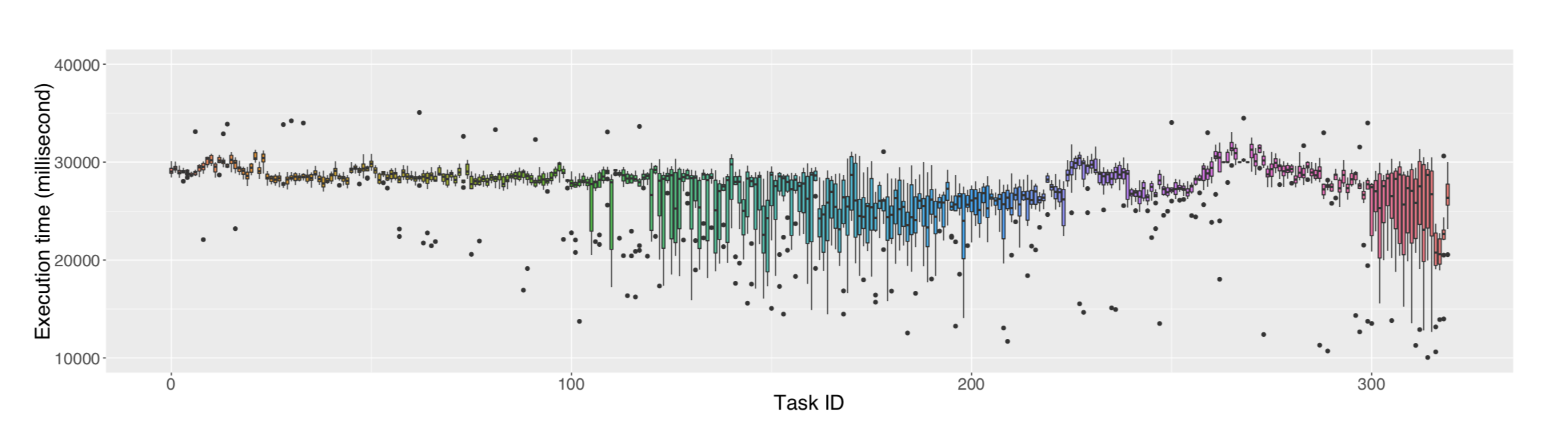
[Objective 3] An adaptive job scheduling framework for stream data applications.
ANR Funded Participantes: Thomas Lambert
An adaptive job scheduling framework will be developed on the top of KERSTREAM. The framework will be accommodated with several scheduling polices that can be adaptively tuned in response to the application’s behavior and requirement.
[D 3.1] Computing infrastructures (Clouds and Edge) differ in terms of capacity but they share other properties including heterogeneous and multi-tenancy. When sharing cloud resources, fairness, consolidation and performance come into question. For instance, how can we keep preserving high system utilization and avoiding QoS violation of the diverse applications. We have been working on investigating these metrics (fairness, resource utilization) in shared data-intensive clusters (Paper Under evaluation) and at different stages of the execution of data-intensive applications (reading and writing data from/to SSDs and provisioning containers and VMs to run data-intensive applications).In addition, we introduced new method to handle cross-rack data communications and a resource provisioning method that considers system variations for data-intensive workflows in multi-tenant clouds. These works were realized in collaboration with Orcun Yildiz, Jad Darrous, Hai Jin, and Song Wu and resulted in two publications in IPDPS 2019 , CCGrid 2018, ICCCN 2019 , TBD19, ICPP 2019,and one paper under evaluation. With Thomas Lambert, we plan to use the findings of these works and the results from [D 1.3] to extended our scheduler to consider multiple data-intensive applications in cloud and edge environments.